What Is the Threat Intelligence Lifecycle?
The threat intelligence lifecycle is the repeating six-phase process security teams use to turn raw data into finished intelligence that drives decisions: planning, collection, processing, analysis, dissemination, and feedback. Each pass feeds the next, so the output of one cycle sharpens the questions you ask at the start of the following one.
Most teams meet the model as a tidy diagram with six arrows in a circle. Reality is messier. In our work tracking coordinated narrative attacks across Eastern Europe, a single “phase” often runs three times before the next one even starts — collection stalls, analysts push requirements back, and the loop bends to fit the threat. That friction is the point. The cycle exists to impose discipline on a problem that never sits still.
It helps to separate two words people use interchangeably. Data is the unsorted pile: IP addresses, domains, leaked credentials, a spike in bot accounts. Intelligence is what survives after a human analyst weighs that data against a specific question a decision-maker actually asked. The lifecycle is the machinery that moves you from the first to the second, on repeat.
Why a Loop Beats a Linear Checklist
A loop beats a checklist because threats adapt the moment you act on them, and a one-way process has no built-in way to catch up. Block a botnet’s command server today and the operators rotate infrastructure by Friday. A linear playbook ends; the lifecycle restarts and absorbs that change.
The circular design also fixes a quieter failure: intelligence nobody uses. When feedback closes the loop, analysts learn which reports changed a decision and which got skipped. Over a few cycles, that signal trims wasted collection and points scarce analyst hours at the questions that carry real weight. You stop producing intelligence for its own sake and start producing it for the person who has to act.
The Six Phases at a Glance
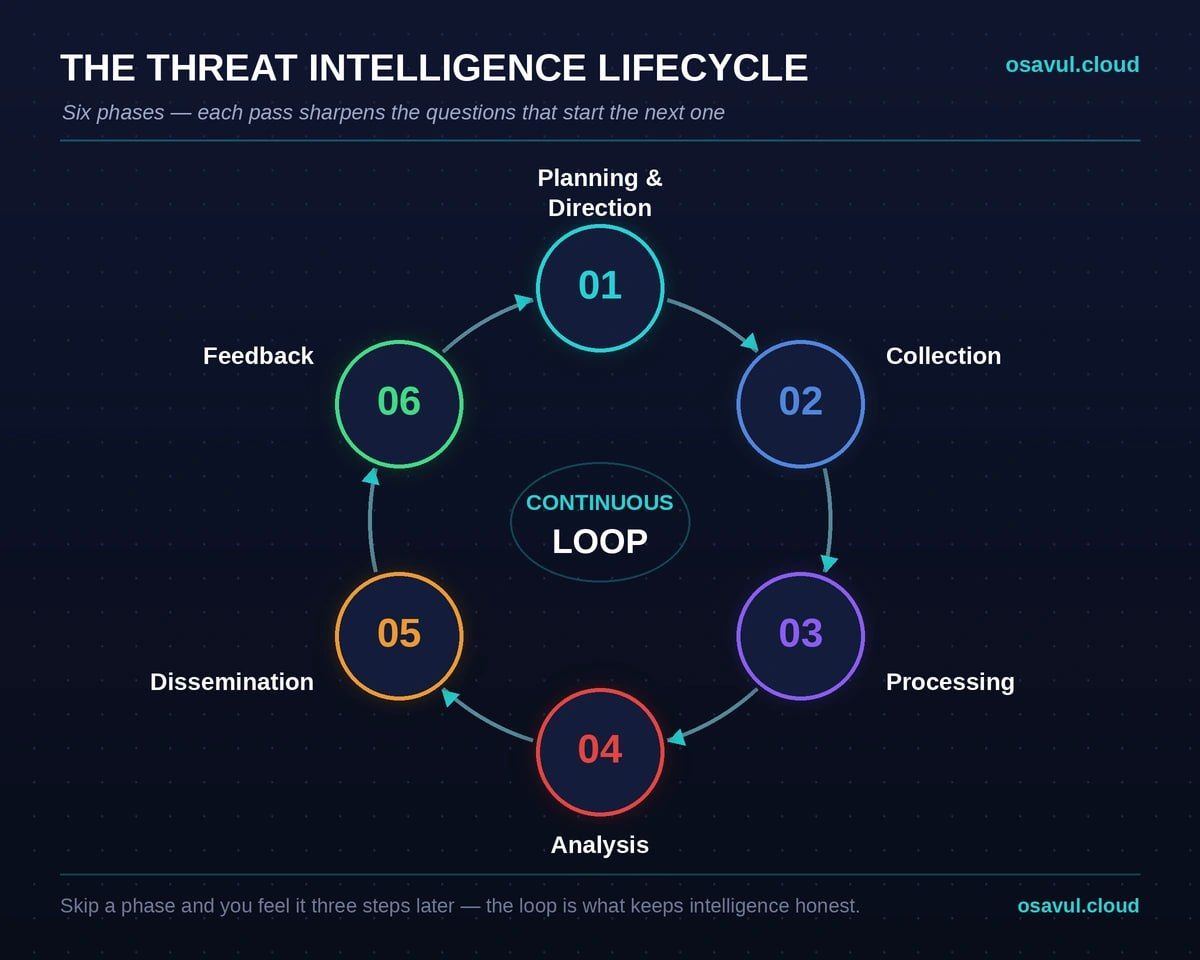
The six phases of the threat intelligence lifecycle are planning and direction, collection, processing, analysis, dissemination, and feedback. Read top to bottom, they answer four plain questions: what do we need to know, where do we get it, what does it mean, and who needs to hear it. The table below maps each phase to its job, its main output, and the role that usually owns it.
Core question | |||
| 1. Planning & Direction | What do decision-makers need to know? | Priority intelligence requirements (PIRs) | CTI lead, CISO |
| Where does the data come from? | |||
| How do we make the data usable? | |||
| 4. Analysis | What does the evidence actually mean? | Assessments, threat reports, scored indicators | Intelligence analysts |
| 5. Dissemination | Who acts on this, and in what format? | Briefings, alerts, machine-readable IOCs | Analysts, SOC liaison |
| 6. Feedback | Did it change a decision? | Refined requirements for the next cycle | Stakeholders, CTI lead |
Two things tend to surprise people seeing this laid out. First, real analytical work — phase four — sits late in the sequence; the three steps before it exist purely to protect that analyst’s time. Second, ownership shifts hands at almost every row, which is exactly why handoffs are where the threat intelligence process most often leaks.
A quick note on lineage. This model descends directly from the classic intelligence cycle used by national agencies for decades, adapted for cyber defense. The bones are the same. What changed is volume and speed: a government desk officer might run this cycle over weeks, while a modern SOC compresses it into hours against an automated adversary.
Phase 1: Planning and Direction
Planning and direction is the first phase of the threat intelligence lifecycle, where teams define what they need to learn and why before any data gets collected. It sets the scope, names the decision-makers who will use the output, and ranks questions so the rest of the cycle aims at what matters instead of whatever is easiest to grab.
Skip this phase and you feel it three steps later. Collection balloons, analysts drown in indicators with no clear question to answer, and the final report lands on a desk where nobody asked for it. We’ve watched well-funded teams pull terabytes of social data and still fail to tell a client whether a specific campaign targeted their brand — because nobody pinned down that question on day one.
Good planning is a conversation, not a form. The CTI lead sits with the people who own risk — security leadership, fraud, sometimes comms or legal — and translates their worries into answerable intelligence problems. “Are we exposed?” becomes “Which of our executives appear in credential dumps from the last 90 days, and on which forums?”
Writing Priority Intelligence Requirements (PIRs)
A priority intelligence requirement is a specific, decision-linked question that directs collection and analysis toward a single gap in what leadership knows. A strong PIR is narrow enough to answer with evidence and tied to an action someone will take based on the result.
The difference between a vague ask and a usable PIR is concrete:
- Weak: “Tell us about ransomware threats.” (No actor, no asset, no decision.)
- Strong: “Which ransomware operators are actively targeting regional healthcare providers our size, and what initial-access methods do they favor?” (Bounded, actionable, measurable.)
Rank your PIRs and revisit them every cycle. Threats move, business priorities move, and a requirement that mattered last quarter can quietly go stale. The feedback phase exists partly to retire dead PIRs and promote new ones — which is how planning stops being a one-time kickoff and becomes the steering wheel for the whole threat intelligence process.
Phase 2: Collection
Collection is the phase where teams gather raw data from the sources most likely to answer their priority intelligence requirements. It covers everything from open-source material and technical telemetry to paid feeds and human reporting, with the PIRs from phase one deciding what’s worth pulling and what’s noise.
The trap here is volume mistaken for value. More sources feel safer, but every feed you add is a feed someone has to process, store, and eventually trust. We tell teams to collect against a question, never “just in case.” A collection plan that maps each source to a specific PIR is the cheapest quality control you will ever run.
Sources: OSINT, Technical Feeds, and Human Reporting
Threat intelligence collection draws on three broad source types: open-source intelligence (OSINT), technical and machine data, and human-derived reporting. Most mature programs blend all three, because each covers the blind spots of the others.
- OSINT — public posts, forums, paste sites, domain registrations, and social platforms. It’s wide and cheap, but the signal-to-noise ratio is brutal. Investigators chasing coordinated activity on messaging platforms know this well; the discipline of structured OSINT collection on networks like Telegram turns a flood of chatter into traceable leads.
- Technical data — malware samples, IOCs, DNS records, network telemetry, and honeypot output. High fidelity, but it tells you what happened more than who or why.
- Human reporting — ISAC sharing, vetted vendor briefings, and trusted peer networks. Government bodies like CISA build much of their value here, on the idea that shared reporting beats isolated defense.
Choosing Threat Intelligence Feeds That Earn Their Keep
The best threat intelligence feeds are the ones aligned to your sector, your tech stack, and your active PIRs — not the ones with the highest indicator count. A feed pushing a million IOCs a day is worthless if 990,000 never touch your environment.
Judge a feed before you ingest it against four plain criteria:
The question to ask | |
| Relevance | Do these indicators map to threats my sector actually faces? |
| How fast does an indicator land here after first observation? | |
| Does each indicator arrive with the why — actor, campaign, confidence? | |
| Overlap | How much of this duplicates feeds I already pay for? |
Context is the criterion teams underrate most. A bare IP address is a chore. The same IP tagged with the actor using it, the campaign it belongs to, and a confidence score is something an analyst can act on in seconds — which moves the load off people and into phase three.
Phase 3: Processing
Processing is the phase where raw collected data gets converted into a clean, consistent, machine-readable form analysts can actually work with. It covers normalization, enrichment, deduplication, and translation — the plumbing that sits between a messy data dump and a dataset worth opening.
Nobody brags about this phase. There’s no dramatic finding, no briefing to the board. But here’s what we’ve seen over and over: the difference between a team that’s drowning and a team that’s sharp usually isn’t talent or budget. It’s how much of this grunt work they’ve handed to machines. When an analyst spends the first two hours of the day renaming fields and deleting duplicate rows, that’s two hours stolen from the actual job — and it happens far more than anyone admits.
Normalization, Enrichment, and Deduplication
These three operations turn scattered inputs into one coherent dataset. Think of them as three different messes, each with its own fix.
Normalization tackles inconsistency. Pull from twenty sources and you get twenty dialects — timestamps written five ways, indicator types labeled by whoever happened to log them. Normalization forces all of it into a single schema so nothing gets lost in translation. Standards like STIX exist for exactly this reason: so one tool can hand intelligence to another without garbling it.
Enrichment tackles emptiness. An indicator almost always shows up naked — a domain, a hash, nothing else. Enrichment dresses it: registration date, hosting history, related samples, the actor already tied to it. Suddenly the analyst is reading a story instead of squinting at a string.
Deduplication tackles repetition. The same malicious IP gets reported by ten feeds, and without dedup your dataset says “ten threats” when it means one. Done well, the tenth sighting doesn’t clutter the record — it raises your confidence in it.
Then there’s language, which teams forget until it bites them. We track narratives across a dozen languages at once, and raw collection lands in all of them. If processing doesn’t translate, transliterate, and tag entities first, the same actor surfaces under three different spellings — and your analysis quietly falls apart before it begins.
One line keeps this phase honest: processing should change a data point’s form, never its meaning. The second your cleanup starts dropping inconvenient outliers, you’re not processing anymore. You’re analyzing — without the rigor the next phase is supposed to bring.
Phase 4: Analysis
Analysis is the phase where processed data becomes finished intelligence — where analysts judge what the evidence means, how much to trust it, and what it implies for the people who asked the question. This is the heart of the whole cycle. Everything before it exists to get a skilled human to this moment with clean material and time to think.
The job is judgment, not retrieval. A processed dataset can tell you that an actor registered forty domains last week. Only an analyst can say whether that’s a staging effort against your sector, routine churn, or a deliberate feint — and how confident anyone should be in that read. Machines narrow the field; humans make the call.
Turning Indicators Into Assessments People Can Act On
A good assessment connects observed evidence to a clear judgment, states a confidence level, and spells out what it means for the reader’s decision. The shift is from “here’s what we saw” to “here’s what we think it means, here’s how sure we are, and here’s what you should weigh because of it.”
A few habits separate analysis that holds up from analysis that embarrasses you later:
- Map behavior, not just indicators. IPs and hashes rot in days. Attacker behavior persists. Tying activity to adversary techniques in MITRE ATT&CK gives an assessment a shelf life longer than the next infrastructure rotation.
- State confidence honestly. “High confidence” and “we’re guessing” are both fine to write — pretending the second is the first is how teams lose their stakeholders’ trust.
- Separate the method from the message. How you reach a conclusion matters as much as the conclusion. In disinformation work, choosing between narrative analysis and thematic analysis changes what patterns you even see — and the same care applies to any analytic technique.
Bias is the quiet enemy here. Confirmation bias nudges an analyst toward the read that matches yesterday’s, and a tight cycle makes that worse, not better. The teams we trust most build in friction on purpose — a peer review, a devil’s-advocate pass, a structured technique — so speed doesn’t quietly trade away accuracy. Finished intelligence is only as good as the thinking behind it, and that thinking deserves a check before it ships.
Phase 5: Dissemination
Dissemination is the phase where finished intelligence reaches the people who need it, in the format each can actually use. The same finding might leave the building three ways at once — a one-line alert to the SOC, a short paragraph to an executive, a machine-readable indicator set pushed straight to the firewall. A report nobody can act on may as well never have been written.
Here’s the painful part: this is where good analysis dies most often. Not in collection, not in analysis — here. We once watched a team produce a genuinely excellent assessment of a coordinated campaign, then bury it in a 40-page PDF. The one executive who needed page 31 never got past page two. The thinking was right. The delivery wrecked it. And that story is depressingly common, because smart analysts tend to assume the work speaks for itself. It doesn’t. Somebody has to make it speakable.
Matching the Report to the Reader

Effective dissemination tailors format, depth, and timing to the audience — because a SOC analyst and a CISO want opposite things from the exact same finding. One needs an indicator to block in the next five minutes. The other needs the business risk, in plain English, before the Monday leadership call. Hand each the other’s version and you’ve helped no one.
It sounds obvious written down. In the rush of a live incident it’s the first thing to go, so the teams that stay disciplined decide the format before they write a word:
What they need | ||
| SOC / responders | Indicators to action now | Machine-readable IOCs, alerts |
| Behavior, TTPs, context | ||
| Risk, exposure, options | ||
| Executives / board | Business impact, trend | One-page summary, plain language |
And then there’s timing, which quietly outranks everything in this table. A flawless report that lands after the decision is already made is worth nothing — sometimes less than nothing, because all it really tells leadership is that you were too slow. The teams maturing fastest treat dissemination like a delivery with a hard deadline, not a victory lap once the analysis is “finished.” Clarity and speed are what make intelligence stick. Length never has.
Phase 6: Feedback
Feedback is the phase where stakeholders tell the intelligence team what worked, what missed, and what they need next — closing the loop and steering the following cycle. It’s the step that turns a one-off process into a learning one, and it’s the step almost everyone skips when things get busy.
The reason it gets cut is simple: feedback feels like overhead when the next fire is already burning. But skipping it is how teams keep answering questions nobody asks anymore. Without it, collection drifts, reports get longer and less read, and a year later you’re staffing a function that produces a great deal and changes very little.
Real feedback is more specific than “good report, thanks.” The questions that move a program forward are blunt: Did this assessment change a decision you made? What did we tell you that you already knew? What did you need that wasn’t there? We push stakeholders for those answers directly, because polite silence is the most expensive response in this whole cycle.
What comes back here doesn’t just tweak the next report — it rewrites phase one. A requirement that mattered last quarter gets retired. A blind spot someone hit during an incident becomes a new priority intelligence requirement. The dead weight in a feed someone never used gets cut from the collection plan. That’s the loop actually closing: feedback at the end of one threat intelligence lifecycle becomes the direction at the start of the next.
And the cycle never really stops. Each pass should leave the team a little faster, a little more focused, and a little better at telling signal from noise than the pass before. A program that isn’t improving across cycles isn’t running the lifecycle — it’s just repeating the motions.
Where the Threat Intelligence Process Breaks Down
The threat intelligence process most often fails at the seams between phases — not inside them. Individual steps usually work; it’s the handoffs, the skipped feedback, and the collection that drifts loose from any real question that quietly drain a program’s value. Knowing where the cracks form is half of preventing them.
A handful of failure patterns show up again and again, across teams of every size:
- Collection with no question behind it. Feeds get added because they’re available, not because a PIR asked for them. The result is a swelling dataset and a shrinking signal. If you can’t name the requirement a source serves, that source is cost, not capability.
- The analysis bottleneck. Automation speeds up collection and processing, then dumps everything on a human team that didn’t grow. Indicators pile up faster than anyone can judge them, and “real-time intelligence” becomes a backlog with a nicer name.
- Dissemination as an afterthought. Strong analysis gets buried in a format the reader won’t open or arrives after the decision’s been made. The intelligence existed; it just never landed.
- The feedback loop that never closes. No one asks whether reports changed decisions, so requirements ossify and the team keeps answering last year’s questions with this year’s budget.
- Tool sprawl with no through-line. A separate product for each phase, none of them talking, so analysts spend their day copying data between tabs instead of thinking.
There’s a human cost threaded through all of these: burnout. Analysts who spend their days wrangling data instead of interpreting it leave, and they take hard-won context out the door with them. Most of these failures trace back to one root cause — too much manual labor wedged into a cycle that moves faster every year. Which is exactly the pressure that pushes teams toward automation.
How Automation Reshapes the CTI Lifecycle
Automation reshapes the CTI lifecycle by absorbing the high-volume, repetitive work in collection, processing, and dissemination — so human analysts spend their hours on the one phase that genuinely needs them: analysis. Done right, it doesn’t replace the analyst. It clears the desk in front of them.
Look back at where the cycle breaks and the pattern is consistent: the failures cluster in the phases built on repetition. Those are precisely the phases machines handle well. Collecting from a thousand sources at once, normalizing a dozen languages into one schema, deduplicating overlapping feeds, pushing the right format to the right reader on time — none of that needs human judgment. All of it eats human hours when done by hand.
Here’s the shift worth sitting with. For most of this discipline’s history, scaling intelligence meant hiring more analysts. That math no longer holds against an adversary who automates their own side — coordinated bot networks, AI-generated narratives, infrastructure that rotates faster than any human can track by hand. You can’t out-staff a machine. You can only meet it with one.
That’s the gap modern platforms are built to close. Systems like Osavul take on the collection, processing, and detection load across the cycle — surfacing coordinated narrative attacks and threat activity at a scale and speed manual review can’t reach — and hand analysts enriched, prioritized material instead of raw noise. The analyst still makes the call. They just make it with hours of grunt work already done, and a clearer view of what actually warrants their attention.
The point isn’t automation for its own sake. It’s rebalancing the cycle. When machines carry collection and processing, the analytical phase finally gets the time and focus it always deserved — and the whole threat intelligence lifecycle moves at something close to the speed of the threats it’s meant to counter.
Frequently Asked Questions
What are the six stages of the threat intelligence life cycle?
The six stages are planning and direction, collection, processing, analysis, dissemination, and feedback. The thing to hold onto is that they’re a loop, not a to-do list — planning sets the questions, the middle four stages grind data into finished intelligence, and feedback hands what you learned back to planning so the next pass starts smarter. Drawn as a line, it lies to you. Drawn as a circle, it’s honest.
How is the threat intelligence lifecycle different from the traditional intelligence cycle?
Not by much, on paper — and that surprises people. The model is the cyber adaptation of the classic intelligence cycle that national agencies have run for decades, and the stages line up almost one to one. What actually changed is the clock. A government desk officer might work a cycle over weeks; a security team today often has hours, because the adversary on the other side automates their own side of the fight.
How long does one full intelligence cycle take?
Anywhere from minutes to months — and if someone gives you a single number, be skeptical. A request to block a live, fast-moving threat can close in under an hour. A deep read on an actor circling your sector might take weeks of patient work. In practice the better teams don’t pick one speed; they run several cycles at once, each paced to the question it’s answering.
Where do threat intelligence feeds fit in the process?
Feeds live in the collection stage, supplying the technical raw material — malicious IPs, domains, file hashes. But here’s the catch we see teams learn the hard way: a feed is only as useful as it is relevant to your environment and the context riding along with each indicator. Volume is a vanity metric. And whatever a feed delivers still has to survive processing and analysis before anyone should call it intelligence.
What’s the most common reason the cycle fails?
Collecting without a question behind it. It’s the quiet killer — analysts end up buried under indicators nobody asked for, and the signal drowns. A close second is the feedback stage that never really happens, so requirements quietly go stale and the team keeps answering last year’s questions on this year’s budget. Both problems share one root: too much manual labor jammed into a cycle that keeps speeding up.